AI Agent Workflow Orchestration:构建智能工作流编排系统的深度指南
深入探讨 AI Agent 工作流编排的核心概念、架构模式与实战实践,从单一 Agent 到多 Agent 协作的完整技术路径
开篇:从单兵作战到团队协作
2026 年,AI Agent 技术已经从「单一工具调用」进化到「复杂工作流编排」。当我们谈论 Agent 时,不再是一个孤立的聊天机器人,而是一个能够协调多个工具、多个子 Agent、甚至多个外部系统来完成复杂任务的智能编排系统。
如果你已经掌握了 Tool Calling 的基础——让模型调用函数、读取文件、访问 API——那么下一步就是解决更复杂的问题:
- 如何让 Agent 完成需要 10+ 个步骤的长任务?
- 如何在多个 Agent 之间分配职责和协调工作?
- 如何设计容错、可恢复的工作流?
- 如何监控和调试复杂的 Agent 行为?
本文将系统性地回答这些问题,从工作流编排的核心概念出发,深入剖析主流架构模式,最终给出可落地的工程实践。
第一层:理解工作流编排的本质
什么是工作流编排?
工作流编排(Workflow Orchestration)是指定义、管理和执行一系列相互依赖的任务的过程。在 AI Agent 上下文中,工作流编排解决的核心问题是:
如何让 LLM 驱动的 Agent 可靠地完成复杂、多步骤的任务。
考虑一个实际场景:用户说「帮我分析这家公司的财务状况并生成报告」。这需要:
- 理解用户意图(公司是谁?需要哪些财务指标?)
- 获取财务数据(调用 API、搜索公开信息)
- 计算关键指标(营收增长率、利润率、现金流)
- 进行对比分析(与行业平均、竞争对手)
- 生成可视化图表
- 撰写分析报告
- 格式化输出
传统编程中,这是一个硬编码的流程。但在 Agent 系统中,每一步都可能需要 LLM 的决策:数据不全怎么办?指标计算用哪种方法?报告写给谁看?
编排 vs. 链式调用
最简单的编排形式是链式调用(Chaining):
输入 → Agent A → Agent B → Agent C → 输出这适合确定性强的任务。但真实世界更复杂:
┌─→ Agent B1 ─┐
输入 → Agent A ─────┼─→ Agent B2 ─┼─→ Agent D → 输出
└─→ Agent B3 ─┘
↑
条件分支真正的编排需要处理:
- 分支逻辑:根据中间结果选择不同路径
- 并行执行:多个独立任务同时进行
- 状态管理:跨步骤共享和传递数据
- 错误恢复:部分失败后的重试或降级
- 监控追踪:全链路的可观测性
工作流编排的核心模型
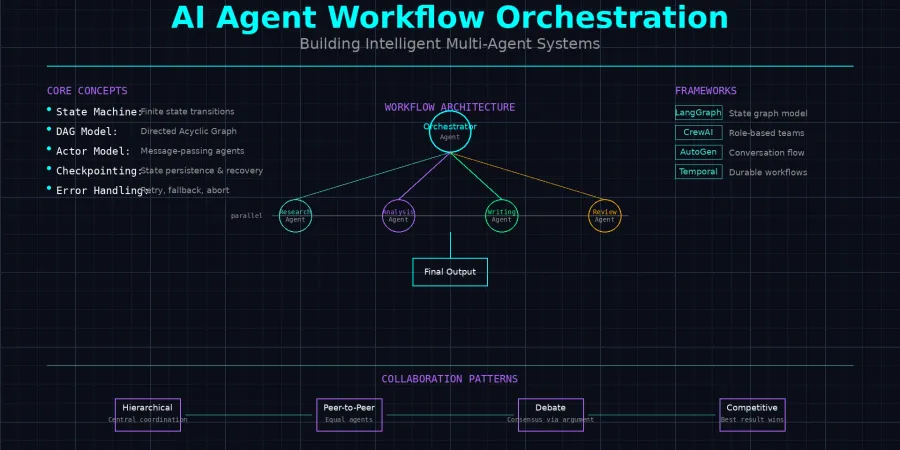
业界主流的工作流模型有三种:
1. 状态机模型(State Machine)
class WorkflowState(Enum):
INIT = "init"
FETCHING_DATA = "fetching_data"
ANALYZING = "analyzing"
GENERATING_REPORT = "generating_report"
COMPLETED = "completed"
FAILED = "failed"
def transition(current_state: WorkflowState, event: str) -> WorkflowState:
transitions = {
(WorkflowState.INIT, "start"): WorkflowState.FETCHING_DATA,
(WorkflowState.FETCHING_DATA, "success"): WorkflowState.ANALYZING,
(WorkflowState.FETCHING_DATA, "error"): WorkflowState.FAILED,
# ...
}
return transitions.get((current_state, event), current_state)2. DAG 模型(Directed Acyclic Graph)
workflow:
name: financial_analysis
tasks:
- id: fetch_income_statement
type: api_call
params:
endpoint: /api/financials/income
- id: fetch_balance_sheet
type: api_call
params:
endpoint: /api/financials/balance
- id: calculate_ratios
type: llm_task
depends_on:
- fetch_income_statement
- fetch_balance_sheet
- id: generate_report
type: llm_task
depends_on:
- calculate_ratios3. Actor 模型
每个 Agent 是一个独立的 Actor,通过消息传递协作:
class AnalystAgent(Actor):
async def receive(self, message):
if message.type == "analyze":
result = await self.analyze(message.data)
await self.send(message.sender, result)
class ReportAgent(Actor):
async def receive(self, message):
if message.type == "generate":
report = await self.generate(message.data)
await self.send(message.sender, report)第二层:主流编排框架对比
LangGraph:图状态管理
LangGraph 是 LangChain 团队推出的工作流编排框架,核心思想是将 Agent 工作流建模为状态图:
from langgraph.graph import StateGraph, END
# 定义状态
class AgentState(TypedDict):
messages: List[Message]
next_action: str
# 定义节点
def research_node(state: AgentState) -> AgentState:
# 执行研究任务
return {"next_action": "analyze"}
def analyze_node(state: AgentState) -> AgentState:
# 执行分析任务
return {"next_action": "report"}
# 构建图
workflow = StateGraph(AgentState)
workflow.add_node("research", research_node)
workflow.add_node("analyze", analyze_node)
workflow.add_node("report", report_node)
# 定义边
workflow.add_edge("research", "analyze")
workflow.add_edge("analyze", "report")
workflow.add_edge("report", END)
# 条件边
workflow.add_conditional_edges(
"research",
lambda state: state["next_action"],
{"analyze": "analyze", "research": "research"} # 循环支持
)优势:
- 明确的状态管理
- 支持循环和条件分支
- 内置 checkpointing(状态持久化)
- 与 LangChain 生态无缝集成
劣势:
- 学习曲线较陡
- 复杂图的可视化困难
- 调试需要理解状态流转
CrewAI:角色扮演多 Agent
CrewAI 采用「团队协作」隐喻,每个 Agent 扮演特定角色:
from crewai import Agent, Task, Crew
researcher = Agent(
role="Senior Research Analyst",
goal="Uncover cutting-edge developments in AI",
backstory="You are an experienced researcher with a passion for AI",
tools=[search_tool, scrape_tool]
)
writer = Agent(
role="Tech Content Writer",
goal="Create engaging articles about AI trends",
backstory="You are a skilled writer with deep tech knowledge",
tools=[write_tool]
)
research_task = Task(
description="Research the latest AI Agent frameworks",
agent=researcher,
expected_output="A comprehensive report on AI Agent frameworks"
)
write_task = Task(
description="Write an article based on the research",
agent=writer,
context=[research_task], # 依赖前一个任务
expected_output="A published article"
)
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, write_task],
process=Process.sequential # 或 Process.hierarchical
)
result = crew.kickoff()优势:
- 直观的「角色-任务-团队」抽象
- 支持顺序和层级两种执行模式
- 内置任务委托(Agent 可以把任务交给其他 Agent)
- 丰富的预定义工具集
劣势:
- 粒度控制不如代码级编排
- 角色定义对输出质量影响大
- 复杂逻辑需要自定义 Process
AutoGen:多 Agent 对话框架
微软的 AutoGen 采用「对话」作为核心协调机制:
from autogen import AssistantAgent, UserProxyAgent
assistant = AssistantAgent(
name="assistant",
system_message="You are a helpful AI assistant.",
llm_config={"model": "gpt-4"}
)
user_proxy = UserProxyAgent(
name="user_proxy",
human_input_mode="NEVER",
code_execution_config={"work_dir": "coding"}
)
# 创建群聊
from autogen import GroupChat, GroupChatManager
groupchat = GroupChat(
agents=[assistant, user_proxy, critic, executor],
messages=[],
max_round=12
)
manager = GroupChatManager(groupchat=groupchat)
user_proxy.initiate_chat(manager, message="Build a dashboard for stock analysis")优势:
- 自然的对话式协调
- 支持人类介入(Human-in-the-loop)
- 内置代码执行沙箱
- 强大的可扩展性
劣势:
- 对话轮数多时成本高
- 控制流不如显式编程清晰
- 需要 careful prompt 设计
框架选择指南
| 场景 | 推荐框架 | 理由 |
|---|---|---|
| 需要精确控制流程 | LangGraph | 状态图模型精确可控 |
| 快速原型多角色协作 | CrewAI | 角色定义简单直观 |
| 需要灵活的 Agent 对话 | AutoGen | 对话协调机制成熟 |
| 已有 LangChain 项目 | LangGraph | 无缝集成 |
| 需要人类审批节点 | AutoGen / LangGraph | 都支持 HIL 模式 |
第三层:设计可靠的工作流系统
1. 状态管理策略
工作流的核心是状态管理。有三种主要模式:
模式 A:集中式状态
class WorkflowContext:
def __init__(self):
self.data = {}
self.history = []
def set(self, key: str, value: Any):
self.data[key] = value
self.history.append({"action": "set", "key": key, "timestamp": now()})
def get(self, key: str, default=None):
return self.data.get(key, default)
# 所有节点共享同一个 context
context = WorkflowContext()
execute_node_a(context)
execute_node_b(context)模式 B:消息传递
@dataclass
class NodeOutput:
data: dict
metadata: dict
next_node: str
def node_a(input: dict) -> NodeOutput:
result = process(input)
return NodeOutput(
data={"intermediate": result},
metadata={"confidence": 0.95},
next_node="node_b"
)模式 C:事件溯源(Event Sourcing)
class WorkflowEvent:
type: str
payload: dict
timestamp: datetime
class EventStore:
def append(self, event: WorkflowEvent):
self.events.append(event)
def replay(self) -> WorkflowState:
state = initial_state()
for event in self.events:
state = apply(state, event)
return state2. 错误处理与重试
Agent 工作流中,错误是常态而非异常。设计健壮的错误处理机制至关重要:
分层错误处理:
class ErrorHandler:
def handle(self, error: Exception, context: dict) -> RecoveryAction:
# 第一层:可重试错误
if isinstance(error, (RateLimitError, TimeoutError)):
return RetryAction(delay=exponential_backoff(context["retry_count"]))
# 第二层:可降级错误
if isinstance(error, APINotAvailableError):
return FallbackAction(use_backup=True)
# 第三层:需要人工介入
if isinstance(error, HallucinationDetectedError):
return HumanReviewAction()
# 第四层:不可恢复
return AbortAction(reason=str(error))重试策略:
async def execute_with_retry(
task: Callable,
max_retries: int = 3,
backoff_base: float = 2.0
):
for attempt in range(max_retries):
try:
return await task()
except RetryableError as e:
if attempt == max_retries - 1:
raise
delay = backoff_base ** attempt
await asyncio.sleep(delay)3. 检查点与恢复
长时间运行的工作流需要支持中断恢复:
class CheckpointManager:
def save(self, workflow_id: str, state: dict, node_id: str):
checkpoint = {
"workflow_id": workflow_id,
"state": state,
"current_node": node_id,
"timestamp": datetime.utcnow()
}
self.storage.save(checkpoint)
def restore(self, workflow_id: str) -> Optional[Checkpoint]:
return self.storage.get_latest(workflow_id)
# 使用
async def execute_workflow(workflow_id: str):
checkpoint = checkpoint_manager.restore(workflow_id)
if checkpoint:
# 从检查点恢复
state = checkpoint.state
start_node = checkpoint.current_node
else:
# 从头开始
state = initial_state()
start_node = "start"
for node in workflow.nodes_from(start_node):
state = await node.execute(state)
checkpoint_manager.save(workflow_id, state, node.id)4. 监控与可观测性
复杂工作流需要全链路监控:
import structlog
logger = structlog.get_logger()
class ObservableNode:
def __init__(self, node_id: str):
self.node_id = node_id
self.metrics = MetricsCollector()
async def execute(self, state: dict) -> dict:
with logger.context(node_id=self.node_id):
logger.info("node_started", state_keys=list(state.keys()))
start_time = time.time()
try:
result = await self._execute(state)
logger.info(
"node_completed",
duration=time.time() - start_time,
output_keys=list(result.keys())
)
self.metrics.record_success(self.node_id)
return result
except Exception as e:
logger.error(
"node_failed",
error=str(e),
duration=time.time() - start_time
)
self.metrics.record_failure(self.node_id)
raise第四层:多 Agent 协作模式
模式一:层级式协作(Hierarchical)
中心 Agent 分配任务给子 Agent:
┌──────────────┐
│ Orchestrator │
│ Agent │
└──────┬───────┘
│
┌─────────────┼─────────────┐
│ │ │
┌───▼───┐ ┌───▼───┐ ┌───▼───┐
│ Agent │ │ Agent │ │ Agent │
│ A │ │ B │ │ C │
└───────┘ └───────┘ └───────┘class OrchestratorAgent:
def __init__(self):
self.specialists = {
"research": ResearchAgent(),
"analysis": AnalysisAgent(),
"writing": WritingAgent()
}
async def execute(self, task: str) -> str:
# 分解任务
subtasks = await self.decompose(task)
results = []
for subtask in subtasks:
specialist = self.select_specialist(subtask)
result = await specialist.execute(subtask)
results.append(result)
# 合并结果
return await self.synthesize(results)模式二:对等式协作(Peer-to-Peer)
多个 Agent 平等协作:
class PeerAgent:
def __init__(self, name: str, expertise: str):
self.name = name
self.expertise = expertise
self.peers = []
async def collaborate(self, task: str) -> str:
# 自己先处理
my_result = await self.process(task)
# 请求同伴评审
for peer in self.peers:
feedback = await peer.review(my_result)
if feedback.needs_revision:
my_result = await self.revise(my_result, feedback)
return my_result模式三:辩论式协作(Debate)
多个 Agent 通过辩论达成共识:
async def debate_round(
agents: List[Agent],
topic: str,
rounds: int = 3
) -> str:
positions = {}
for round_num in range(rounds):
for agent in agents:
# 每个 Agent 表达观点或反驳
position = await agent.argue(
topic,
previous_positions=positions,
round=round_num
)
positions[agent.name] = position
# 最终由 judge agent 总结
return await judge_agent.synthesize(positions)模式四:竞争式协作(Competitive)
多个 Agent 并行处理,选择最佳结果:
async def competitive_execution(
task: str,
agents: List[Agent],
judge: JudgeAgent
) -> str:
# 并行执行
results = await asyncio.gather(*[
agent.execute(task) for agent in agents
])
# 评判选择
best_result = await judge.select_best(results)
return best_result第五层:实战案例 - 智能研究报告生成系统
让我们把前面的概念整合成一个完整的案例:
from dataclasses import dataclass
from typing import List, Optional
import asyncio
# === 状态定义 ===
@dataclass
class ResearchState:
topic: str
collected_data: dict
analysis_results: dict
report_draft: str
final_report: str
current_stage: str
errors: List[str]
# === Agent 定义 ===
class ResearchOrchestrator:
def __init__(self):
self.data_collector = DataCollectorAgent()
self.analyst = AnalystAgent()
self.writer = WriterAgent()
self.reviewer = ReviewerAgent()
async def run(self, topic: str) -> str:
state = ResearchState(
topic=topic,
collected_data={},
analysis_results={},
report_draft="",
final_report="",
current_stage="init",
errors=[]
)
# 阶段 1:数据收集
state = await self._collect_data(state)
# 阶段 2:分析
state = await self._analyze(state)
# 阶段 3:撰写
state = await self._write(state)
# 阶段 4:审核
state = await self._review(state)
return state.final_report
async def _collect_data(self, state: ResearchState) -> ResearchState:
sources = [
self.data_collector.search_web(state.topic),
self.data_collector.query_database(state.topic),
self.data_collector.fetch_reports(state.topic)
]
results = await asyncio.gather(*sources, return_exceptions=True)
for i, result in enumerate(results):
if isinstance(result, Exception):
state.errors.append(f"Source {i} failed: {result}")
else:
state.collected_data.update(result)
state.current_stage = "analysis"
return state
async def _analyze(self, state: ResearchState) -> ResearchState:
# 多角度分析
analysis_tasks = [
self.analyst.trend_analysis(state.collected_data),
self.analyst.competitive_analysis(state.collected_data),
self.analyst.risk_assessment(state.collected_data)
]
results = await asyncio.gather(*analysis_tasks)
state.analysis_results = {
"trends": results[0],
"competition": results[1],
"risks": results[2]
}
state.current_stage = "writing"
return state
async def _write(self, state: ResearchState) -> ResearchState:
# 迭代写作
outline = await self.writer.create_outline(state.analysis_results)
sections = await self.writer.write_sections(outline)
state.report_draft = await self.writer.assemble(sections)
state.current_stage = "review"
return state
async def _review(self, state: ResearchState) -> ResearchState:
# 审核循环
for _ in range(3): # 最多 3 轮修订
feedback = await self.reviewer.review(state.report_draft)
if feedback.approved:
break
state.report_draft = await self.writer.revise(
state.report_draft,
feedback.comments
)
state.final_report = state.report_draft
state.current_stage = "completed"
return state
# === 执行 ===
async def main():
orchestrator = ResearchOrchestrator()
report = await orchestrator.run("AI Agent 编排框架对比分析")
print(report)
asyncio.run(main())第六层:最佳实践与陷阱规避
实践一:明确的边界定义
每个 Agent 应该有清晰的职责边界:
# 好的设计
class DataCollectorAgent:
"""负责数据收集,不做分析"""
class AnalystAgent:
"""负责数据分析,不做写作"""
# 坏的设计
class DoEverythingAgent:
"""既收集数据又分析又写作"""实践二:输入输出契约
使用强类型定义 Agent 接口:
from pydantic import BaseModel
class CollectorOutput(BaseModel):
data_points: List[DataPoint]
sources: List[str]
confidence: float
class AnalystInput(BaseModel):
data_points: List[DataPoint]
analysis_type: str
def collector_to_analyst(output: CollectorOutput) -> AnalystInput:
return AnalystInput(
data_points=output.data_points,
analysis_type="comprehensive"
)实践三:幂等性设计
确保工作流可以安全重试:
@idempotent(key=lambda x: x.request_id)
async def process_request(request: Request) -> Result:
# 多次调用结果一致
return await compute(request)常见陷阱
陷阱一:过度分解
不是每个步骤都需要一个独立的 Agent。过度分解会增加协调成本:
# 过度分解
agents = [
GetURLAgent(),
MakeRequestAgent(),
ParseResponseAgent(),
ExtractDataAgent()
]
# 合理设计
agents = [
WebScraperAgent(), # 包含上述所有能力
]陷阱二:忽略 LLM 非确定性
同样的输入可能产生不同的输出,需要处理:
async def call_llm_with_validation(prompt: str, schema: type) -> dict:
for attempt in range(3):
response = await llm.call(prompt)
try:
return schema.parse_raw(response)
except ValidationError:
# 重试并提供 schema 提示
prompt = f"{prompt}\n\nOutput must match: {schema.schema_json()}"
raise MaxRetriesExceeded()陷阱三:状态污染
跨步骤的状态需要谨慎管理:
# 危险:状态被意外修改
state.data["key"].append(new_item) # 影响后续步骤
# 安全:使用不可变模式
new_state = state.with_update(data={**state.data, "key": updated_list})第七层:未来展望
Agent 工作流的演进方向
1. 自适应工作流
未来的工作流将不再是预定义的图,而是根据任务动态生成:
class AdaptiveOrchestrator:
async def plan(self, task: str) -> Workflow:
# LLM 根据任务动态规划工作流
plan = await self.planner.generate_plan(task)
return Workflow.from_plan(plan)2. 学习型编排
系统从历史执行中学习优化:
class LearningOptimizer:
def suggest_optimization(self, workflow: Workflow) -> Workflow:
# 分析历史数据
patterns = self.analyze_execution_history()
# 建议优化
return self.apply_optimizations(workflow, patterns)3. 人机协作原生
人类不是作为异常处理,而是工作流的一等公民:
workflow.add_node(
HumanApprovalNode(
timeout=timedelta(hours=24),
fallback=AutoApprovalAction()
)
)结语
工作流编排是 AI Agent 从「玩具」走向「生产」的关键技术。从简单的链式调用到复杂的多 Agent 协作,从硬编码的流程到自适应的编排,这个领域正在快速演进。
核心要点回顾:
- 理解模型:状态机、DAG、Actor 是三种核心编排模型
- 选对工具:LangGraph、CrewAI、AutoGen 各有适用场景
- 设计可靠:状态管理、错误处理、检查点、监控是四大支柱
- 协作模式:层级、对等、辩论、竞争是四种典型模式
- 避免陷阱:明确边界、定义契约、保证幂等、控制粒度
当你能够设计出既灵活又可靠的 Agent 工作流系统时,你就掌握了构建复杂 AI 应用的核心能力。